DynamicX 视觉组学习笔记 - 基于 svm 算法的车牌识别
学习车牌识别的相关知识和实践对于我来说还是有一些困难的,我也是在这次学习 svm 的过程中开始了解机器学习的基础知识。这一次我看了很多博客文章,内容参差不齐,有些仅仅描述流程,对于具体代码以“加群”“关注公众号”为理由设置门槛;有些则给出了及其完善的代码,却缺乏文字介绍,在这些里面给予我帮助最大的两个开源项目是EasyPR和yinxiucheng/OpencvCarRecgnize,前者是著名的开源车牌识别项目,后者的作者提供了详细的思路介绍。 在这次的��学习中我遇到了不少困难,其中一个是 svm 算法理论与实践的割裂,svm 的数学原理比较复杂,我看过几次之后仍然是一知半解,但至少理解了 svm 在二维空间中的计算方式和支持向量这个概念。而在实践上由于是使用 opencv 包装的 svm 算法,SVM 类的成员函数众多,参数复杂,我仅仅是跟着例程将图片的 HOG 特征送入 svm 训练和判断,对于这个封装的更多细节,有没有其他方式将图片信息送入 svm 也不太清楚。另一个是 svm 的训练,有很多例程仅仅包含了读取 xml 文件运行 predict 的过程,并没有给出训练并导出 xml 文件的方法,而在我跟着另一个模型训练的例程尝试的时候又遇到了一些诸如读取 xml 文件报错、训练效果差等问题。还有一个是字符识别阶段的实现方式,有很多例程都使用了 opencv 封装的 ann,但是 ann 的原理更难看懂,也不是此次的主题,所以我尝试过使用 svm 进行字符识别,我查到了一些使用 svm 进行图形验证码识别的例程,但是识别字符就不是识别车牌那样简单的二分类,在车牌的字符识别上也鲜有人使用 svm,说明 svm 在这里并不十分合适,并且由于时间的关系,尝试的过程中遇到了很多不明不白的报错,这一个尝试并没有成功。 总的来说最后实现识别并标记车牌号的代码几乎没有多少是自己写的,也没有像之前分水岭算法那样对每一行的作用、原理都十分清楚,还是有些可惜的。
理论基础
Sobel 边缘检测
索贝尔算子是计算机视觉领域的一种重要处理方法。主要用于获得数字图像的一阶梯度,常见的应用和物理意义是边缘检测。索贝尔算子是把图像中每个像素的上下左右四领域的灰度值加权差,在边缘处达到极值从而检测边缘。 索贝尔算子主要用作边缘检测。在技术上,它是一离散性差分算子,用来运算图像亮度函数的梯度之近似值。在图像的任何一点使用此算子,将会产生对应的梯度矢量或是其法矢量。 索贝尔算子不但产生较好的检测效果,而且对噪声具有平滑抑制作用,但是得到的边缘较粗,且可能出现伪边缘。
在边缘检测中,常用的一种模板是 Sobel 算子。Sobel 算子有两个,一个是检测水平边缘的 ;另一个是检测垂直边缘的 。与 Prewitt 算子相比,Sobel 算子对于象素的位置的影响做了加权,可以降低边缘模糊程度,因此效果更好。 Sobel 算子另一种形式是各向同性 Sobel(Isotropic Sobel)算子,也有两个,一个是检测水平边缘的 ,另一个是检测垂直边缘的 。各向同性 Sobel 算子和普通 Sobel 算子相比,它的位置加权系数更为准确,在检测不同方向的边沿时梯度的幅度一致。将 Sobel 算子矩阵中的所有 2 改为根号 2,就能得到各向同性 Sobel 的矩阵。 由于 Sobel 算子是滤波算子的形式,用于提取边缘,可以利用快速卷积函数, 简单有效,因此应用广泛。美中不足的是,Sobel 算子并没有将图像的主体与背景严格地区分开来,换言之就是 Sobel 算子没有基于图像灰度进行处理,由于 Sobel 算子没有严格地模拟人的视觉生理特征,所以提取的图像轮廓有时并不能令人满意。
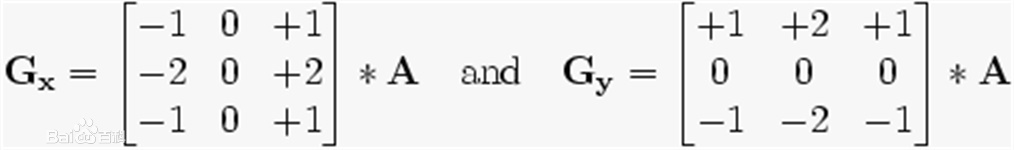
HOG 特征
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。HOG 特征通过计算和统计图像局部区域的梯度方向直方图来构成特征。
来源 特征描述符就是通过提取图像的有用信息,并且丢弃无关信息来简化图像的表示。HOG 特征描述符可以将 3 通道的彩色图像转换成一定长度的特征向量。那么我们就需要定义什么是“有用的”,什么是“无关的”。这里的“有用”,是指对于什么目的有用,显然特征向量对于观察图像是没有用的,但是它对于像图像识别和目标检测这样的任务非常有用。当将这些特征向量输入到类似支持向量机(SVM)这样的图像分类算法中时,会得到较好的结果。那什么样的“特征”对分类任务是有用,比如我们想检测出马路上的车道线,那么我们可以通过边缘检测来找到这些车道线,在这种情况下,边缘信息就是“有用的”,而颜色信息是无关的。在 HOG 特征描述符中,梯度方向的分布,也就是梯度方向的直方图被视作特征。图像的梯度(x 和 y 导数)非常有用,因为边缘和拐角(强度突变的区域)周围的梯度幅度很大,并且边缘和拐角比平坦区域包含更多关于物体形状的信息。方向梯度直方图(HOG)特征描述符常和线性支持向量机(SVM)配合使用,用于训练高精度的目标分类器。
HOG 的提取步骤
- 色彩和伽马归一化
- 计算图像梯度
- 构建方向的直方图
- 将细胞单元组合成大的区间
- 收集 HOG 特征
SVM
SVM 是一种二类分类模型,SVM 的基本模型是定义在特征空间上的间隔最大的线性分类器,SVM 的学习策略是间隔最大化。
支持向量机(英语:support vector machine,常简称为 SVM,又名支持向量网络)是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM 训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM 模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。
前面第一句的定义简单清晰地表达了 SVM 的特点,在使用时需要对算法细节有更多的了解才能明白各个主要参数的作用,算法讲解部分直接放几个链接
阿泽的知乎专栏 - 【机器学习】支持向量机 SVM 野风的知乎专栏 - 支持向量机(SVM)——原理篇 TangShusen - 看了这篇文章你还不懂 SVM 你就来打我
代码实践
在查阅了很多资料后我发现目前车牌识别的思路已经有了共识,大体上分三个步骤:车牌定位、字符分割、字符识别。
svm 训练
void train_svm() {
vector<string> pos_files;
pos_files = getFiles(SVM_POS);
for(auto file: pos_files){
svm_data.push_back({SVM_POS+file,1});
}
vector<string> neg_files;
neg_files = getFiles(SVM_NEG);
for(auto file: neg_files){
svm_data.push_back({SVM_NEG+file, -1});
}
Mat samples;
vector<int> responses;
for(auto data:svm_data){
auto image = imread(data.file);
if (image.empty()) {
printf("加载样本失败 image: %s.\n", data.file.c_str());
continue;
}
cvtColor(image, image, CV_BGR2GRAY);
//二值
threshold(image, image, 0, 255, THRESH_BINARY+THRESH_OTSU);
Mat feature;
//获得hog特征
getSvmHOGFeatures(image, feature);
//调整为一行
feature = feature.reshape(1, 1);
// 图片数据:x x x
// samples:x x x
// x x x
//保存特征数据
samples.push_back(feature);
//记录对应的标签
responses.push_back(data.label);
}
//训练数据 行
Ptr <TrainData> trainData = TrainData::create(samples, SampleTypes::ROW_SAMPLE, responses);
printf("训练数据准备完成,开始训练!\n");
//其他参数都是默认值
//为了把最后一个参数设置true 则会创建更平衡的验证子集也就是如果是2类分类的话能得到更准确的结果
svm = SVM::create();
svm->setType(SVM::C_SVC);//惩罚因子C,默认为0
//设置采用的核函数
//SVM::POLY默认值,当数据量比较大的时候 VM::POLY 是个不错的选择
svm->setGamma(SVM::SIGMOID);
//设置 C-SVC, epsilon-SVR, and nu-SVR的惩罚因子数(优化),默认值是0
svm->setC(100);
/*
终止条件类型
TermCriteria::Type 有三个:COUNT, EPS or COUNT + EPS
TermCriteria::Type::COUNT 小于最大迭代次数或者元素数
TermCriteria::Type::MAX_ITER 同上
TermCriteria::Type::EPS 当达到所要求的精度或者参数变化是即停止迭代
//设置终止条件 ,最大迭代10W次
//所要求精度:是0.0001 就是 0.01%
//classifier->setTermCriteria(TermCriteria(TermCriteria::Type::COUNT,10*10000,0.0001));
cvTermCriteria同样设置终止条件
Type::有三个
CV_TERMCRIT_ITER 小于最大迭代次数或者元素数
CV_TERMCRIT_NUMBER 同上
CV_TERMCRIT_EPS 当达到所要求的精度或者参数变化是即停止迭代
*/
// 训练的终止条件,迭代20000次,
//0.00001: 迭代过程中,允许输入数据进行一定的变异,这个变异的比率最高要求的精度是0.0001 ,0.01%
svm->setTermCriteria(cvTermCriteria(CV_TERMCRIT_ITER, 20000, 0.0001));
svm->trainAuto(trainData, 10, SVM::getDefaultGrid(SVM::C),
SVM::getDefaultGrid(SVM::GAMMA), SVM::getDefaultGrid(SVM::P),
SVM::getDefaultGrid(SVM::NU), SVM::getDefaultGrid(SVM::COEF),
SVM::getDefaultGrid(SVM::DEGREE), true);
svm->save( SVM_XML );
printf("训练完成 ,模型保存 \n");
}
车牌定位
考虑到本次使用的测试数据都是光线充足环境的蓝牌正拍照片,车牌在照片中有如下几个特征:
- 颜色为蓝底白字,由于亮蓝色车漆的车比较少见,所以车牌的蓝底是比较容易区分的。
- 形状为固定尺寸的长方形,长边与短边分别与图片长边与短边平行,可能有些许倾斜变形
- 由于文字字母的存在,车牌区域图像数值变化幅度大且频繁
- 与车上或背景中的其他文字相比,车牌文字往往更大更清晰
而车牌定位就是利用以上几个特征从照片中寻找出可能是车牌的区域并进行判断。我查找到的寻找方式有
- 通过色彩分割获得车牌底色。这种方式对照片的色彩要求比较高,取值范围也比较难控制。
- 利用车牌位置数值变化大信息密集的特点通过滤镜、形态学、边缘检测等操作寻找车牌,很难调出具有普适性的参数。
- 在进行一系列过滤操作后通过查找图片上的水平垂直边并判断长宽比来寻找车牌,对拍摄角度要求较高。
- 通过神经网络查找,目前还是我的知识盲区。
在很多例子中都是多种查找方式同时使用以提高识别率。在查找到可能的车牌后需要一一判定是否真的是车牌,很显然,在本次环境下查找到的真车牌和假车牌会有非常明显的差别,svm 在这里就可以派上用场了。
//通过颜色查找车牌部分
//转成HSV
Mat hsv;
cvtColor(src, hsv, COLOR_BGR2HSV);
int chanles = hsv.channels();
int h = hsv.rows;
int w = hsv.cols * 3;
//判断数据是否为一行存储的
//内存足够的话 mat的数据是一块连续的内存进行存储
if (hsv.isContinuous()) {
w *= h;
h = 1;
}
for (size_t i = 0; i < h; ++i) {
//第i 行的数据 hsv的数据 uchar = java byte
uchar *p = hsv.ptr<uchar>(i);
for (size_t j = 0; j < w; j += 3) {
int h = int(p[j]);
int s = int(p[j + 1]);
int v = int(p[j + 2]);
bool blue = false;
//蓝色
if (h >= 100 && h <= 124 && s >= 43 && s <= 255 && v >= 46 && v <= 255) {
blue = true;
}
if (blue){
p[j] = 0;
p[j + 1]=0;
p[j + 2]=255;
}else {
//hsv 模型 h:0 红色 亮度和饱和度都是0 ,也就变成了黑色
p[j] = 0;
p[j + 1] = 0;
p[j + 2] = 0;
}
}
}
//把h、s、v分离出来
vector<Mat> hsv_split;
split(hsv, hsv_split);
//二值化
Mat shold;
threshold(hsv_split[2], shold, 0, 255, THRESH_OTSU + THRESH_BINARY);
//闭操作
Mat close;
Mat element = getStructuringElement(MORPH_RECT, Size(17, 3));
morphologyEx(shold, close, MORPH_CLOSE, element);
//查找轮廓
vector<vector<Point>> contours;
findContours(close, contours, RETR_EXTERNAL, CHAIN_APPROX_NONE);
//通过Sobel查找车牌部分
Mat blur;
//高斯模糊
GaussianBlur(src, blur, Size(5, 5), 0);
Mat gray;
//灰度化
cvtColor(blur, gray, COLOR_BGR2GRAY);
Mat sobel_16;
//Sobel边缘检测
Sobel(gray, sobel_16, CV_16S, 1, 0);
Mat sobel;
convertScaleAbs(sobel_16, sobel);
//二值化
Mat shold;
threshold(sobel, shold, 0, 255, THRESH_OTSU + THRESH_BINARY);
//闭操作
Mat close;
Mat element = getStructuringElement(MORPH_RECT, Size(17, 3));
morphologyEx(shold, close, MORPH_CLOSE, element);
//查找轮廓
vector<vector<Point>> contours;
findContours(close, contours, RETR_EXTERNAL, CHAIN_APPROX_NONE);
//获取HOG特征部分
Mat trainImg = Mat(hog->winSize, CV_32S);
resize(src, trainImg, hog->winSize);
vector<float> d;
hog->compute(trainImg, d, Size(8, 8));
Mat features(d);
//特征矩阵
features.copyTo(out);
features.release();
trainImg.release();
//SVM验证部分
vector<Mat> plates;
plates.insert(plates.end(), sobel_plates.begin(), sobel_plates.end());
plates.insert(plates.end(), color_plates.begin(), color_plates.end());
int index = -1;
float minScore = FLT_MAX;
for (int i = 0; i < plates.size(); ++i) {
Mat plate = plates[i];
//先灰度化,再二值化
Mat gray;
cvtColor(plate, gray, COLOR_BGR2GRAY);
Mat shold;
threshold(gray, shold, 0, 255, THRESH_OTSU + THRESH_BINARY);
//提取特征
Mat features;
getHogFeatures(svmHog, shold, features);
Mat samples = features.reshape(1, 1);
samples.convertTo(samples, CV_32FC1);
float score = svm->predict(samples, noArray(), StatModel::Flags::RAW_OUTPUT);
if (score < minScore) {
minScore = score;
index = i;
}
gray.release();
shold.release();
features.release();
samples.release();
}
字符分割
成功定位得到车牌图片已经非常符合“证件照”的标准,每个字符所占空间、排列顺序都是比较一致的,考虑到本次不要求识别省份,通过轮廓查找就可以顺利地框选出每一个字符,再通过对大小比例的判断过滤掉非字符的结果就实现了对字符的分割。
bool verityCharSize(Mat src) {
float aspect = 45.0f / 90;
float realAspect = (float)src.cols / src.rows;
float minHeight = 10.0f;
float maxHeight = 35.0f;
float error = 0.7f;
float maxAspect = aspect + aspect * error;
float minAspect = aspect - aspect * error;
if (realAspect >= minAspect && realAspect <= maxAspect && src.rows >= minHeight && src.rows <= maxHeight) {
return true;
}
return false;
}
vector<vector<Point>> contours;
findContours(plate_shold, contours, RETR_EXTERNAL, CHAIN_APPROX_NONE);
vector<Rect> charVec;
for (vector<Point> point:contours) {
Rect rect = boundingRect(point);
Mat p = plate_shold(rect);
if (verityCharSize(p)) {
charVec.push_back(rect);
}
}
//对集合中的矩形按照x进行一下排序,保证它们是从左到右的顺序
sort(charVec.begin(), charVec.end(), [](const Rect &r1, const Rect &r2) {
return r1.x < r2.x;
});
字符识别
到达这一步车牌已经变成了一个个的字母数字图片,这里要做的就是识别出单个字符。
for (size_t i = 0; i < vector.size(); ++i) {
Mat src = vector[i];
Mat features;
//
getHogFeatures(annHog, src, features);
Mat response;
Point maxLoc;
Point minLoc;
Mat samples = features.reshape(1, 1);
ann->predict(samples,response);
//获取最大可信度 匹配度最高的属于31种中的哪一个
minMaxLoc(response, 0, 0, &minLoc, &maxLoc);
int index = maxLoc.x;
result += CHARS[index];
}
结果

